
Requirements
Functional Requirements:
- Generate a unique short URL for a given long URL
- Redirect the user to the original URL when the short URL is accessed
- Support link expiration where URLs are no longer accessible after a certain period
- Allow users to customize their short URLs (optional)
- Example:
Non-Functional Requirements:
- High availability (the service should be up 99% of the time)
- Low latency (URL shortening and redirects should happen in milliseconds)
- Scalability (the system will handle millions of requests per day)
- Durability (shortened URLs should work for default 30 days. Can edit time up to 5 years)
- Security to prevent DDOS, malicious…
Back-of-the-envelope Estimation
Assume
Daily Active User: 1 million requests per day
Read:Write Ratio: 100:1 (for every URL creation, we expect 100 redirects)
Peak Traffic: 5x the average load
URL Lengths: Average original URL length of 100 characters
The Number of Character for Short Url Id: 7 characters
Queries per Second
- Average Redirects per second (RPS): 12 * 100 = 1,200
- Peak RPS: 120 * 100 = 12,000
- Average Writes Per Second (WPS): (1,000,000 requests / 86,400 seconds) ≈ 12
- Peak WPS: 12 ×10 = 120
=> Read:Write Ratio is 100:1
Storage
For each shortened URL, we need to store the following information:
- Short URL: 7 characters
- Original URL: 100 characters (Average)
- Creation Date: 8 bytes (The Number of Characters of Timestamp)
- Expiration Date: 8 bytes (The Number of Characters of Timestamp)
Total storage per URL:
- Storage per URL: 7 + 100 + 8 + 8 =123 bytes
Storage requirements for one year:
- Total URLs per Year: 1,000,000 × 365 = 365,000,000
- Total Storage per Year: 365,000,000 × 123 bytes ≈ 44.895 GB
Storage requirements for 5 years:
- Total URLs per Year: 365,000,000 × 5 = 1,825,000,000
- Total Storage per Year: 44.895 GB × 5 ≈ 224.475 ≈ 2,3T
Bandwidth
Assuming the HTTP 301 or 302 redirect response size is about 200 bytes (including headers and the short URL).
- Total Read Bandwidth per Second: 12,000 x 200 bytes = 2.4MB/s
- Peak Bandwidth: If peak traffic is 10x average, the peak bandwidth could be as high as 12,000 x 10 + 200 bytes = 24MB/s
APIs Design
Main APIs:
POST /api/v1/shorten(original_url, expiry_date=None): short_url- GET
/short_url(short_url): long_url - POST
/api/v1/delete_shorten(short_url): true/false
Non-Main APIs:
/api/v1/modify_expiry_date(short_url, new_expiry_date): true/false
Database Design
let’s consider some factors that can affect our choice:
- We need to store billions of records.
- Most database operations are simple key-value lookups.
- Read queries are much higher than write queries.
- We don’t need joins between tables.
- The database needs to be highly scalable and available.
=> A NoSQL database like DynamoDB or Cassandra is a better option. Because handling billions of simple key-value lookups and providing high scalability and availability
Short Url Table
- short_url(PK): 7 char
- original_url: 100 char
- created_at: Timestamp
- expiration_time: Timestamp
User Table
- Id(PK)
- Password
- Full name
High-Level Design
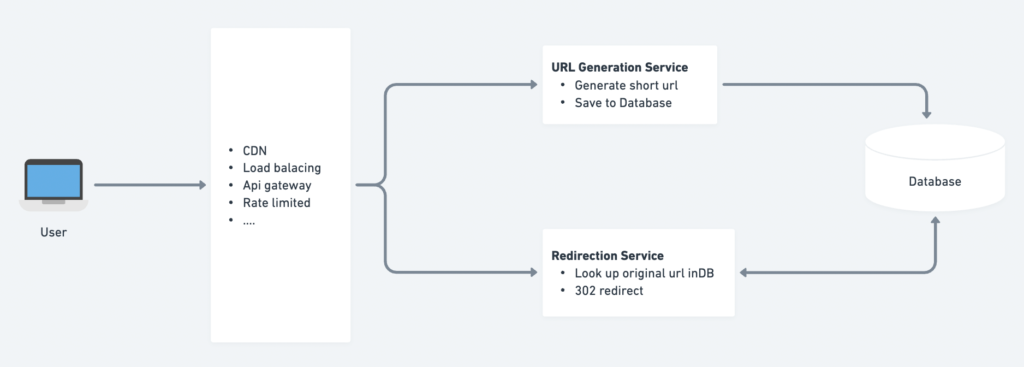
- Load Balancer: Distributes incoming requests across multiple application servers.
- Application Servers: Handles incoming requests for shortening URLs and redirecting users.
- URL Generation Service: Generates short URLs, handles custom aliases, and manages link expirations.
- Redirection Service: Redirects the users to the original URL.
- Database: Stores mappings between short URLs and long URLs.
- Cache: Stores frequently accessed URL mappings for faster retrieval (Optional).
Deep Dives
Which Redirect is Better for a URL Shortener?
1. 301 Redirect (Permanent Redirect)
- Purpose: Indicates that the resource has been permanently moved to a new URL.
- Browser Behavior: Browsers typically cache the 301 redirect. This means future requests for the short URL might bypass your server and go directly to the original long URL.
HTTP/1.1 301 Moved Permanently Location: https://www.original-long-url.com
2. 302 Redirect (Temporary Redirect)
- Purpose: Suggests that the resource is temporarily located at a different URL.
- Browser Behavior: Browsers do not cache the 302 redirects, ensuring that every future request for the short URL goes through your server.
HTTP/1.1 302 Found Location: https://www.original-long-url.com
Result
For most URL shorteners, a 302 redirect is preferred. Here’s why:
- Flexibility:
- You can update or expire short URLs as needed since browsers won’t cache the redirect.
- Analytics:
- Every request passes through your server, allowing you to track click statistics for the short URL.
- Control:
- If the destination of a short URL needs to change, a 302 redirect ensures the update will take effect immediately.
How can we ensure short URLs are unique?
Approach 1: Centralized Counter
Using an auto-increment sequence of numbers is a straightforward way to generate unique IDs for short URLs. Here’s how it works and the pros/cons of the approach:
Implementation:
- Centralized Counter:
- Use a database or a centralized system to maintain an incrementing counter.
- Each request for a new short URL retrieves the next number in the sequence.
- Scaling:
- Scale horizontally by adding multiple servers coordinating with a centralized counter (e.g., a distributed database like Redis or a service like AWS DynamoDB).
Advantages:
- Guaranteed Uniqueness:
- Each number in the sequence is unique, ensuring no duplication of short URLs.
- Simplicity:
- Easy to implement and understand.
- Scalability:
- Proper coordination allows the system to handle increased traffic by adding more servers.
Disadvantages:
- Single Point of Failure (SPOF):
- If the centralized counter fails, the entire system cannot generate new IDs.
- Scalability Limitations:
- The centralized counter can become a bottleneck under high load.
- Predictability:
- Auto-increment numbers can make the sequence predictable, which might not be ideal for security or user privacy.
Potential Solutions to Disadvantages:
Encode the numbers using Base62 or add a random salt to the IDs before converting them to a short URL.
Addressing SPOF:
Use a highly available distributed counter system (e.g., Redis cluster, DynamoDB, or Zookeeper).
Implement fallback mechanisms to a secondary counter in case of failure.
Improving Scalability:
Partition the counter by assigning ranges to different servers (e.g., Server A uses IDs 1-1000, Server B uses 1001-2000).
Use a time-based or shared ID generation strategy (e.g., Snowflake ID).
Hiding Predictability:
Encode the numbers using Base62 or add a random salt to the IDs before converting them to a short URL.
Approach 2: Generating Short URLs (SURLs) Without Global Dependency
This approach leverages hashing and encoding techniques. Here’s how it works, along with the challenges and solutions.
Implementation
- Hashing + Base62 Encoding:
- Generate a hash (e.g., MD5 or SHA256) for the long URL.
- Convert the hash into a Base62 encoded string (using characters
a-z,A-Z,0-9). - Use only the first X characters of the Base62 string (e.g., 8 characters) for the short URL:
Short URL = Base62(Hash(long URL)).first(X)
- Example:
- Long URL:
https://example.com/some-page - MD5 Hash:
c157a79031e1c40f85931829bc5fc552 - Base62 Encoding:
Fk8eJz3R - Short URL (8 chars):
Fk8eJz3R
- Long URL:
Problem: Duplication
Since hashes can collide (different URLs produce the same short URL), duplication is a key challenge.
Solutions
1. Hash + Collision Resolution:
- Maintain a database to store mappings of short URLs to their long URLs.
- If a collision occurs:
- Append or prepend a unique identifier (e.g., timestamp or random value) to the URL before hashing.
- Retry with the modified URL until a unique short URL is generated.
2. Generate UUID + Base62 Conversion:
- Use a UUID (Universally Unique Identifier) instead of hashing:
- Generate a UUID for each long URL.
- Convert the UUID to a Base62 encoded string.
- This method minimizes the risk of collision without requiring retries.
Example:
- UUID:
123e4567-e89b-12d3-a456-426614174000 - Base62:
4kUg2Vb9D
3. Use a Bloom Filter:
- Implement a Bloom filter to quickly check if a short URL already exists.
- If the filter indicates a potential collision, apply collision resolution (as above) or regenerate the short URL.
- This approach reduces the need to query a database frequently.
Advantages
- No Global Dependency: No need for a centralized counter or global state.
- Scalability: Works well with distributed systems.
- Flexibility: Easily extensible for additional features like tracking or analytics.
Disadvantages
- Collision Handling: Requires logic to handle collisions, which can add complexity.
- Hashing Overhead: Hash generation and Base62 encoding add some computational overhead compared to auto-increment IDs.
Recommendation
- Use Hash + Collision Resolution for simplicity if the probability of collisions is low (e.g., with MD5 or SHA256).
- For high-traffic systems, consider UUID + Base62 for better scalability and collision-free guarantees.
- Implement a Bloom filter for quick collision detection and reduced database dependency.
Approach 3: UUID combines Base-62 conversion (Good)
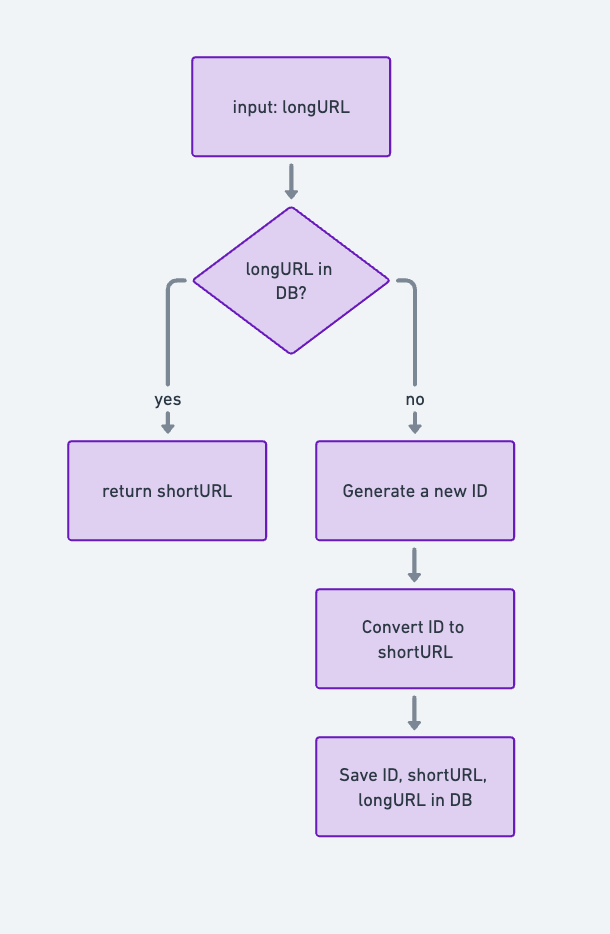
General Idea
- Generate a UUID:
- Use a UUID generator service to create a unique identifier for each long URL.
- A UUID is a 128-bit value that is practically guaranteed to be unique, even in distributed systems.
- Convert the UUID to Base-62:
- Convert the 128-bit UUID into a shorter, URL-friendly format using Base-62 encoding (characters
a-z,A-Z,0-9). - Trim the Base-62 result to a fixed length (e.g., the first 8-12 characters) for compactness.
- Convert the 128-bit UUID into a shorter, URL-friendly format using Base-62 encoding (characters
Why UUID?
- Guaranteed Uniqueness:
- UUIDs are designed to be globally unique, ensuring no collisions even across distributed systems.
- No Global Dependency:
- No need for a centralized counter or hashing mechanism, reducing potential bottlenecks or single points of failure.
- Scalability:
- Works seamlessly in distributed environments without requiring coordination between servers.
Advantages
- No Collision:
- Since UUIDs are unique, collisions are virtually eliminated.
- Distributed System Compatibility:
- UUID generation doesn’t rely on centralized systems, making it highly scalable.
- Simplicity:
- Minimal logic is required for collision detection or resolution.
Disadvantages
- Length:
- UUIDs are relatively long (128 bits). Even after Base-62 encoding, they may result in longer short URLs compared to other methods.
- For example, a UUID converts to 22 Base-62 characters, which might need truncation for compactness.
- Computational Overhead:
- Generating UUIDs and performing Base-62 conversion adds minor computational overhead compared to simpler counter-based methods.
Recommendation
- Use UUID + Base-62 Conversion for systems that prioritize collision avoidance and need to scale across distributed environments.
Approach 4: Distributed UUID Generator (DUUIDG) Using Snowflake (Good)
A Distributed UUID Generator produces unique identifiers across multiple servers in a distributed system. Inspired by Twitter’s Snowflake, this design generates IDs that are unique, sortable, and scalable.
How Distributed UUIDs Work
64-bit Snowflake ID: 1 bit for o | 41 bits for timestamp | 5 bits for Data Center ID | 5 bits for machine ID | 12 bits for sequence |
- Structure of a Distributed UUID (Snowflake Model):
- Timestamp: Ensures IDs are sortable and captured when the ID was created.
- Machine ID: Ensures uniqueness by identifying the server generating the ID.
- Sequence Number: Ensures uniqueness for multiple IDs generated by the same machine within the same timestamp.
- Local and Independent UUID Generation:
- Each server generates IDs independently using its timestamp, machine ID, and sequence number.
- No coordination is required between servers.
Advantages
- Fast:
- IDs are generated locally on each server, eliminating the need for centralized coordination.
- Guaranteed Uniqueness:
- The combination of timestamp, machine ID, and sequence ensures no collisions.
- Sortable:
- IDs are naturally ordered by time, useful for analytics, logging, or processing.
- Scalable:
- Easily supports high request rates across distributed systems.
Disadvantages
- Complexity:
- Building and maintaining a distributed UUID generator adds system complexity.
- Requires precise time synchronization across servers.
- Shifted Challenges:
- Uniqueness, scalability, and availability issues are now pushed to the UUID generator instead of the URL shortening service.
How can we ensure that redirects are fast?
Approach 1: Indexing Techniques
- B-tree Indexing:
- How it works: B-trees are the default indexing method in most relational databases. They create a balanced tree structure for sorting and searching.
- Performance: Provides O(log n) lookup time, making it highly efficient for large datasets.
- Primary Key Indexing:
- How it works: Setting the
short_codecolumn as the primary key automatically enforces an index and ensures uniqueness. - Performance: Offers O(log n) lookups and guarantees data integrity.
- How it works: Setting the
- Hash Indexing:
- How it works: Hash indexing uses a hash table for exact match queries. It is faster than B-trees for lookups but doesn’t support range queries.
- Performance: Provides O(1) average-case lookup time, ideal for exact matches like URL shortener use cases.
Benefits of Indexing
- Faster Lookups: Indexes drastically reduce search times by avoiding full table scans.
- Data Integrity: Primary key indexing ensures the uniqueness of shortcodes.
- Scalable Reads: Indexes allow the database to handle larger datasets efficiently.
Challenges in Scaling
- High Read Volume:
- Example Load:
- 100M daily active users (DAU) performing an average of 5 redirects per day = 500M redirects/day.
- Distributed evenly, this translates to ~5,787 redirects/second.
- Accounting for peak traffic spikes (~100x), the system must handle ~600k read operations/second.
- Example Load:
- Disk I/O Limitations:
- Even with SSDs capable of 100,000 IOPS, the database may struggle to keep up with this high read demand during peak hours.
- Impact on Other Operations:
- High read loads could degrade performance for write operations, such as creating new short URLs, leading to increased latencies.
Approach 2: Using In-Memory Cache to Improve Redirect Speed
To enhance the performance of a URL shortener, an in-memory cache like Redis or Memcached can be introduced between the application server and the database. This optimization allows the system to handle redirects faster by reducing the dependency on slower disk-based storage.
Consider using LRU, and LFU.
How It Works
- Cache Layer:
- The cache stores frequently accessed mappings of short codes to long URLs.
- When a redirect request is received, the application server checks the cache first:
- Cache Hit: If the short code is found, the long URL is retrieved from the cache.
- Cache Miss: If not found, the server queries the database, retrieves the long URL, and stores it in the cache for future requests.
- Performance Impact:
- Memory Access Time: ~100 nanoseconds (0.0001 ms).
- SSD Access Time: ~0.1 milliseconds.
- HDD Access Time: ~10 milliseconds.
- ~1,000 times faster than SSD.
- ~100,000 times faster than HDD.
- Scalability:
- Memory can support millions of reads per second, making it ideal for high-traffic systems.
Challenges
- Cache Invalidation:
- The cache must reflect these changes when URLs are updated or deleted to ensure data consistency.
- While URL updates are rare, invalidation strategies are still necessary to handle edge cases.
- Cache Warm-Up:
- Initially, the cache is empty. Requests may hit the database until the cache is populated.
- Memory Limitations:
- Cache Size: Limited by available memory, requiring careful selection of which entries to cache.
- Eviction Policy: Use strategies like Least Recently Used (LRU) to remove less-used entries when the cache is full.
- System Complexity:
- Adding a cache layer increases system architecture complexity, requiring tradeoff discussions during design.
Approach 3: Content Delivery Networks (CDNs) and Edge Computing
Using CDNs and edge computing can significantly reduce latency for URL redirection by bringing the redirection logic closer to the user. Here’s how it works, the benefits, and the trade-offs.
How It Works
- CDNs for Short URL Domain:
- The short URL domain is served through a CDN with geographically distributed Points of Presence (PoPs).
- CDN nodes cache the mappings of short codes to long URLs.
- When a user requests a short URL, the CDN checks its local cache to resolve the mapping without contacting the origin server.
- Edge Computing:
- Deploy redirection logic directly at the CDN edge using serverless platforms like:
- Cloudflare Workers
- AWS Lambda@Edge
- Fastly Compute@Edge
- The redirection happens at the edge, near the user’s location, avoiding round trips to the primary server.
- Deploy redirection logic directly at the CDN edge using serverless platforms like:
Benefits
- Reduced Latency:
- Redirect requests are processed at the edge, closer to the user, minimizing latency and improving user experience.
- Lower Origin Load:
- Popular short codes are resolved directly by the CDN, reducing the load on the origin server and database.
- Global Scalability:
- The CDN’s distributed infrastructure automatically scales to handle traffic spikes in different regions.
- High Availability:
- If the origin server goes down, cached mappings at CDN nodes can continue serving redirects.
Challenges
- Cache Invalidation:
- Ensuring that stale mappings are invalidated across all CDN nodes is complex and requires proper configuration.
- Edge Computing Constraints:
- Execution Limits: Platforms like Lambda@Edge have constraints on memory, execution time, and available libraries.
- Optimization: Redirect logic must be lightweight to meet edge platform requirements.
- Cost:
- CDNs and edge computing services can be costly, especially for high-traffic volumes.
- Complexity:
- Setting up and managing edge logic requires familiarity with serverless platforms and CDN configuration.
- Debugging and Monitoring:
- Distributed environments make it harder to trace issues compared to centralized servers.
How to implement sharding to distribute data across multiple database nodes?
1. Range-Based Sharding
How It Works
- Data is distributed into ranges based on the shard key.
- Example: For an auto-incrementing ID, assign specific ranges to each shard.
- Shard 1: IDs 1 to 1,000,000.
- Shard 2: IDs 1,000,001 to 2,000,000.
- Shard 3: IDs 2,000,001 to 3,000,000, etc.
Advantages
- Simple to Implement:
- Easy to understand and configure.
- Efficient Range Queries:
- Well-suited for sequential or range-based queries.
Limitations
- Hotspots:
- Uneven load distribution if data isn’t evenly distributed. For instance, if most new data falls into the latest shard.
- Scalability:
- Adding new shards requires manual reorganization of ranges and possible downtime.
2. Hash-Based Sharding
How It Works
- A hash function is applied to the shard key (e.g., short URL or user ID) to determine the shard.
- Example:
shard_number = hash(short_url) % number_of_shards- Shard 1: Data where hash(short_url) % 4 == 0.
- Shard 2: Data where hash(short_url) % 4 == 1, etc.
Advantages
- Even Data Distribution:
- Hashing ensures that data is evenly distributed across shards, reducing hotspots.
- High Scalability:
- Automatically balances load when hash keys are well-distributed.
Limitations
- Scaling Challenges:
- Adding new shards requires rehashing and redistributing data.
- Use consistent hashing to minimize data movement when adding/removing shards.
- Query Complexity:
- Range queries are inefficient, as the query might span multiple shards.
How To Improve Security?
1. Rate Limiting
- Purpose: Prevent abuse by limiting the number of API requests a client can make within a given time.
- Implementation:
- Use tools like Nginx, AWS API Gateway, or libraries like express-rate-limit (Node.js) or django-ratelimit (Python).
- Example: Limit each user to 100 URL shortening requests per hour.
- Store usage metrics in Redis or a similar in-memory store for fast access.
- Benefits:
- Prevents spamming (e.g., creating thousands of URLs in a short time).
- Protects the system from resource exhaustion.
2. Input Validation
- Purpose: Ensure URLs submitted for shortening are safe and valid.
- Implementation:
- Validate URL format using a regular expression or URL parser libraries.
- Block suspicious or potentially malicious URLs (e.g., URLs containing
javascript:,data:, or phishing domains). - Check against a blocklist of known malicious domains or integrate with services like Google Safe Browsing API.
3. HTTP
- Purpose: Encrypt all communications to prevent eavesdropping and man-in-the-middle (MITM) attacks.
- Implementation:
- Use TLS certificates from trusted Certificate Authorities (CAs) like Let’s Encrypt.
- Redirect all HTTP traffic to HTTPS automatically.
4. Monitoring and Alerts
- Purpose: Detect and respond to unusual activity patterns, potential misuse, or security breaches.
- Implementation:
- Logging:
- Log API requests, user activity, and system events.
- Monitoring Tools:
- Use tools like Prometheus, Grafana, or AWS CloudWatch to track metrics such as API request rate, error rate, and traffic patterns.
- Anomaly Detection:
- Flag unusual activity, such as a single IP making excessive requests or accessing known malicious URLs.
- Alerts:
- Trigger alerts for potential DDoS attacks, high error rates, or resource spikes using tools like PagerDuty or Slack integrations.
- Logging:
Additional Security Best Practices
- Authentication and Authorization:
- Use API keys, OAuth, or JWTs to authenticate users and manage access.
- Data Encryption:
- Encrypt sensitive data, such as database fields for URLs and user metadata, using AES encryption.
- DDoS Protection:
- Use services like Cloudflare, AWS Shield, or Google Cloud Armor to mitigate distributed denial-of-service attacks.
- Regular Security Audits:
- Periodically review and test your system for vulnerabilities using tools like OWASP ZAP or Burp Suite.
- Content Security Policy (CSP):
- Add a CSP header to prevent malicious redirects or content injections.
Summary
The URL shortening service is a system design, despite its seemingly simple use case, designing it at the internet scale introduces various complex challenges.
References
https://dev.mysql.com/doc/refman/8.0/en/innodb-auto-increment-handling.html
RELATED POSTS
View all

Scale Application From Zero To Millions Of Users
February 8, 2025 | by [email protected]
