Scale Application From Zero To Millions Of Users
February 8, 2025 | by [email protected]

Designing a system capable of serving millions of users is a big challenge. It’s a process that requires constant refinement and optimization. We start by building a system for a single user and gradually scale it to handle large-scale demands.
Here, We will have an overview system. We will go into detail about each component for the next post.
Single Server
Let’s start with something simple: Everything is running on a single server. That means Code, database, etc., are on a single server.
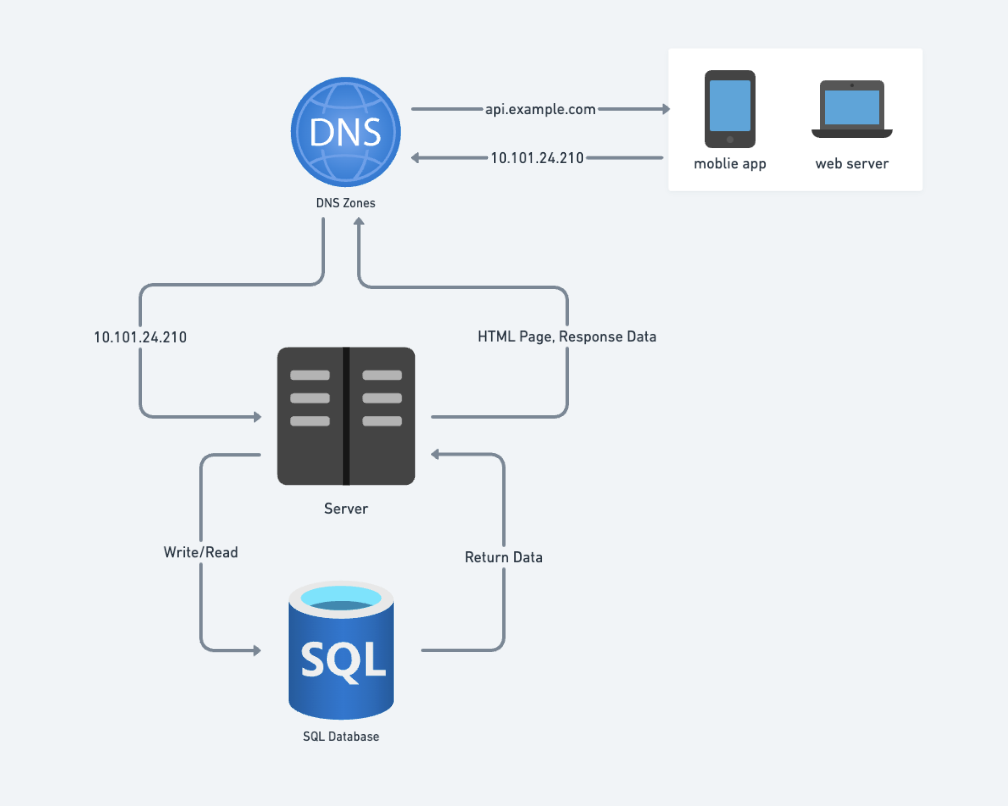
How Users Access Your Website and Server Traffic Flow.
- Domain Name Access: Users visit websites via domain names (e.g.,
api.example.com). DNS, typically a paid service from third parties, resolves this to an IP address. - IP Address Resolution: The browser or mobile app receives the IP address (e.g.,
10.101.24.210). - HTTP Requests: The client sends HTTP requests to the web server using the IP address.
- Database: The database returns JSON data.
- Server Response: The web server returns HTML pages or JSON data for rendering.
Traffic Sources
- Web Application: This type of application uses server-side languages (Java, Python, NodeJs, etc.) for business logic and storage and client-side technologies (HTML, JavaScript) for presentation.
- Mobile Application: Communicates via HTTP, often using JSON for data transfer. Example JSON response:
{
"status": "success",
"data": {
"message": "Hello, World!"
}
}
Vertical Scaling with Horizontal Scaling
Scaling helps your system handle more traffic. Let’s explore two main types:
- Vertical Scaling (Scale Up)
- Adds more resources (CPU, RAM) to a single server.
- Example: Upgrading a server from 8GB to 32GB RAM.
- Advantages: Simple to implement.
- Limitations:
- There’s a limit to how much CPU and memory you can add.
- No failover: If the server fails, the entire system goes offline.
- Horizontal Scaling (Scale Out)
- Adds more servers to distribute the load.
- Example: Instead of upgrading a server, add multiple servers to share traffic.
- Advantages:
- Handles high traffic better.
- Improves redundancy and failover.
Gradually Scaling
Database
Which databases to use?
1. Relational Databases (RDBMS)
- Examples: MySQL, PostgreSQL, Oracle.
- Structure: Data is organized in tables and rows with clear relationships.
- Key Feature: Supports joins for querying related data across multiple tables.
Use Cases:
- You have structured data with defined relationships (e.g., customer orders, inventory).
- Data consistency and ACID transactions are critical (e.g., banking, ERP).
- Your app needs complex queries and report generation.
Example:
A financial system with accounts, transactions, and balances, where relational integrity is crucial.
2. Non-Relational Databases (NoSQL)
- Examples: DynamoDB, MongoDB, Cassandra, Neo4j.
- Categories:
- Key-Value Stores (e.g., Redis)
- Graph Stores (e.g., Neo4j)
- Column Stores (e.g., HBase)
- Document Stores (e.g., MongoDB)
Use Cases:
- Your application requires super-low latency (e.g., gaming leaderboards, chat apps).
- Data is unstructured or does not fit into a traditional schema (e.g., JSON logs).
- You need to serialize/deserialize data formats (e.g., JSON, XML).
- Your system needs to handle massive amounts of data efficiently (e.g., IoT telemetry).
- You need high scalability and distributed storage across multiple nodes.
Example:
A social media app that stores posts and comments as JSON documents and needs to scale globally.
Database Sharding
Database Replication
Database replication is a process where data is copied from one database (master) to others (slaves). This setup improves performance, scalability, and fault tolerance by separating read and write operations.
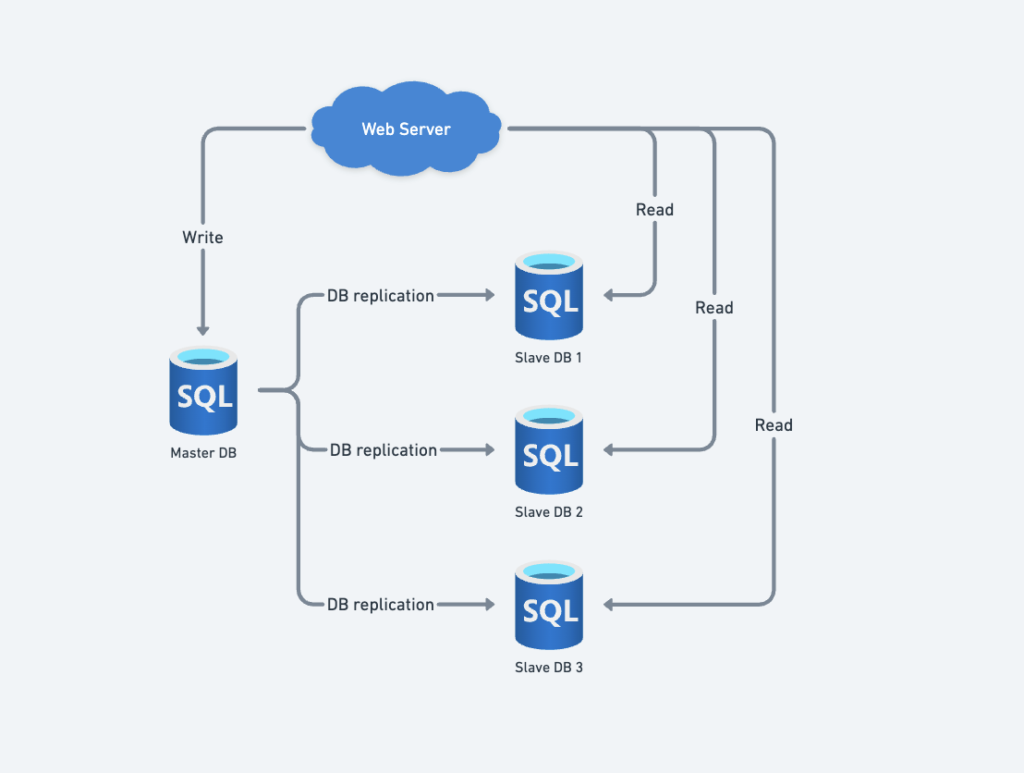
Master-Slave Database
- Master Database:
- Handles write operations (insert, update, delete).
- Acts as the primary source of truth, synchronizing changes to the slave databases.
- Slave Databases:
- Receive copies of data from the master.
- Support only read operations to reduce load on the master.
Advantages of Database Replication
Database replication offers significant benefits in terms of performance, reliability, and availability, making it essential for large-scale and mission-critical applications.
1. Better Performance
- In the master-slave model, write operations are handled by the master, while read operations are distributed among slave nodes.
- This parallel processing improves performance by allowing more queries to be handled simultaneously, reducing load and response times.
Example:
In an e-commerce app, users viewing product details trigger multiple read requests, which are distributed across slave databases to ensure faster page loads.
2. Reliability
- Replication protects against data loss in case of disasters (e.g., typhoons, earthquakes).
- Even if one database server is destroyed, the data remains safe in other replicated servers.
Example:
A global company replicates its data across multiple data centers. If a server in one region is compromised, other regions still have a complete copy of the data.
3. High Availability
- By replicating data across different servers and locations, your application can remain operational even if one database goes offline.
- Users can still access data from another available server, minimizing downtime.
Example:
A social media app ensures 24/7 access by replicating user data across several servers. If a server goes down, other replicas seamlessly handle the load.
Load balancer
A load balancer evenly distributes traffic across multiple web servers, enhancing availability and failover support.
Users connect directly to the load balancer’s public IP, while the load balancer communicates with servers using private IPs for security.
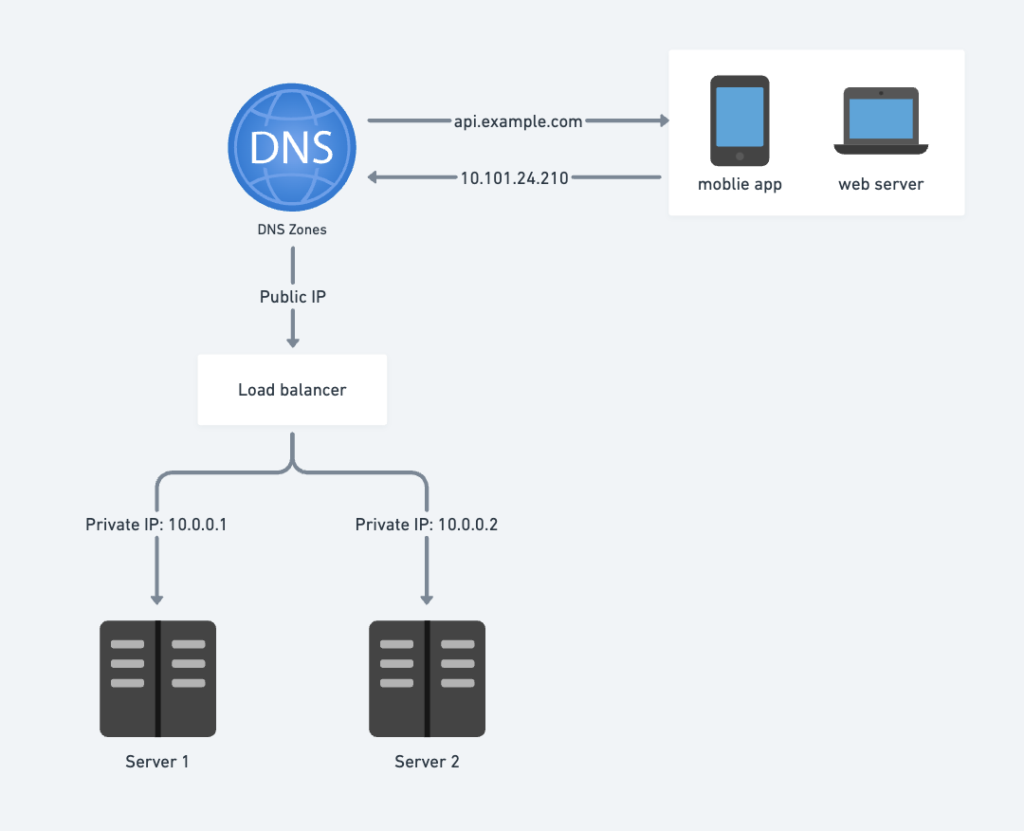
Benefits of Load Balancers
- Improved Failover:
- If server 1 fails, the load balancer redirects all traffic to server 2.
- A new, healthy server can also be added to the pool to maintain redundancy.
- Scalability:
- If traffic spikes and two servers are insufficient, simply add more servers to the pool.
- The load balancer automatically distributes new traffic to these servers, preventing overload.
This is Overview Load Balancers, We will discuss in detail Load Balancers in the next blog.
Cache
The cache is a faster, temporary data store, that sits between the web server and the database.
Benefits of a cache:
- Improved performance by reducing database calls.
- Lower database load, preventing bottlenecks.
- Independent scalability, allows the cache layer to grow without affecting other tiers.
Read-Through Cache Strategy
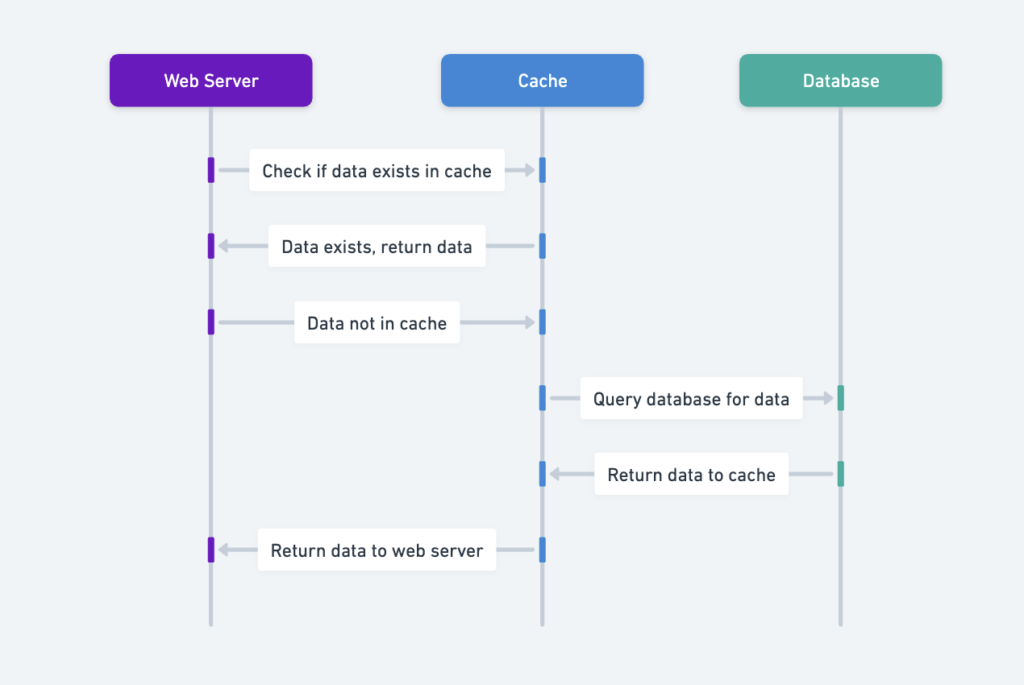
- Step 1: The web server checks the cache for the requested data.
- Step 2: If the cache contains the data, it is sent to the client.
- Step 3: If the cache is empty, the server queries the database, stores the result in the cache, and sends it to the client.
SECONDS = 1
cache.set('myKey', 'hi there', 3600 * SECONDS) # Cache data for 1 hour
response = cache.get('myKey') # Retrieve data from cache
print(response) # Output: hi there
Key Considerations for Using a Cache System
When implementing a cache, it’s important to account for the following factors to optimize performance and reliability:
1. When to Use a Cache
- Use cache when data is read frequently but modified infrequently.
- Cached data is stored in volatile memory, meaning it will be lost if the cache server restarts.
- Critical data should always be stored in persistent data stores like databases to avoid data loss.
Example:
Caching is ideal for read-heavy data, such as product details on an e-commerce website.
2. Expiration Policy
- Implement an expiration policy to remove outdated cached data.
- Avoid expiration times that are too short (causing frequent reloads from the database) or too long (leading to stale data).
Example:
Cache user profile data for 1 hour to balance freshness and performance.
3. Data Consistency
- Maintaining cache consistency with the data store can be difficult, especially with frequent data updates.
- This challenge is amplified in multi-region deployments, where synchronization delays can lead to stale cache data.
Example:
If a user’s profile is updated in the database but not in the cache, future requests may return outdated data.
4. Mitigating Failures
- A single cache server is a single point of failure (SPOF).
- To prevent downtime, deploy multiple cache servers across data centers.
- Overprovision cache memory by a buffer percentage to handle increasing traffic.
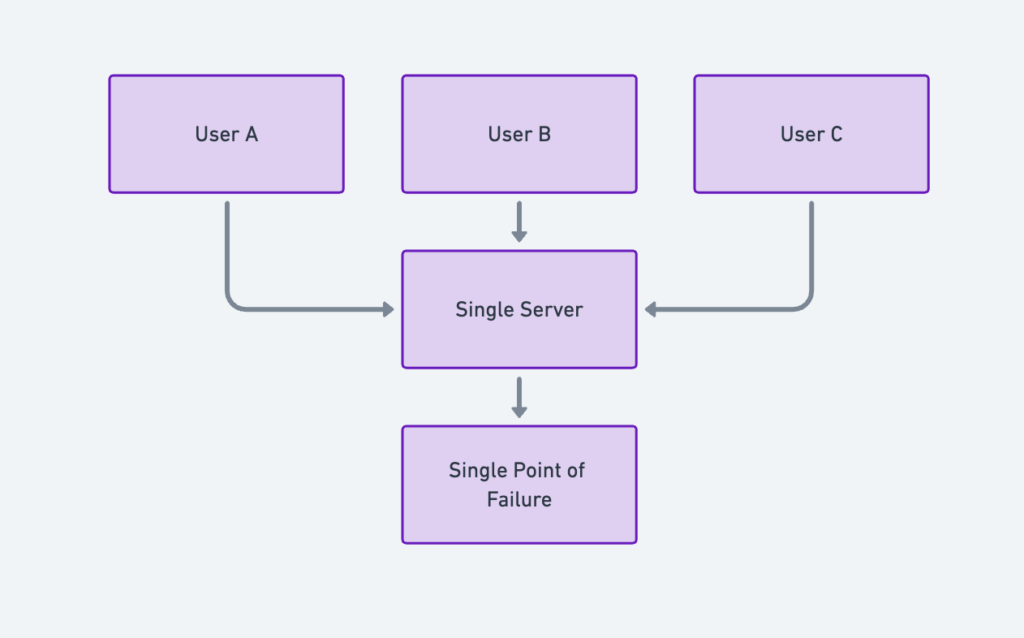
Example:
Set up multiple Redis nodes with replication and failover to ensure cache availability.
5. Eviction Policy
- Once the cache is full, new data will trigger cache eviction, which removes old or less-used items.
- Common eviction policies include:
- Least Recently Used (LRU): Removes items not accessed recently.
- Least Frequently Used (LFU): Removes items accessed the least.
- First In First Out (FIFO): Removes the oldest cached items.
Example:
Use LRU policy for frequently changing content like product recommendations to prioritize the most accessed data.
This is Overview Cache, We will discuss in detail Cache in the next blog.
Content delivery network (CDN)
A Content Delivery Network (CDN) is a system of geographically distributed servers designed to deliver static content quickly to users. Static content includes images, videos, CSS, JavaScript, etc.
Benefits of Using a CDN
- Improved Performance: Reduces load times by serving static content from servers near the user.
- Reduced Server Load: Offloads static content requests from the main web server, freeing resources for dynamic content.
- High Availability: If one CDN server fails, another nearby server can serve the content without interruption.
Here’s a step-by-step workflow of how a CDN serves static content efficiently
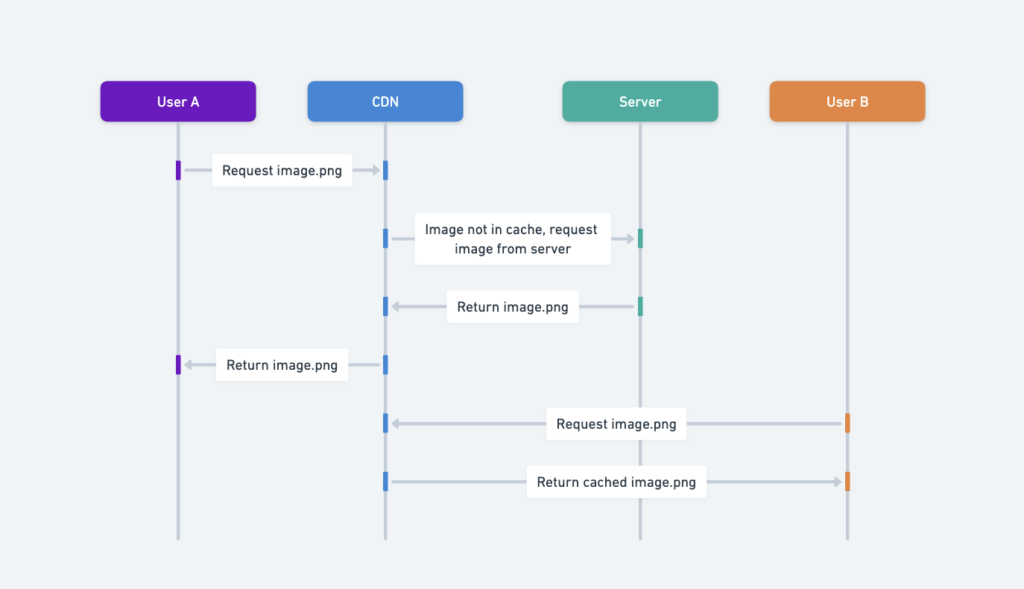
Step 1: User Request
- User A requests
image.pngusing a URL provided by the CDN. - Example URLs for Amazon and Akamai CDNs:
https://example.cloudfront.net/logo.jpghttps://example.com/img/logo.jpg
Step 2: Cache Miss
- If the CDN server does not have the image cached, it forwards the request to the origin (e.g., a web server or storage, such as Amazon S3).
Step 3: Origin Response
- The origin server returns
image.pngto the CDN, along with an HTTP header specifying the Time-to-Live (TTL)—the duration the image should remain cached.
Step 4: Cache Storage
- The CDN stores the image in its cache and sends it to User A.
- The image will remain cached until the TTL expires.
Step 5: Subsequent Requests
- User B sends a request for the same image (
image.png).
Step 6: Cache Hit
- If the TTL has not expired, the CDN serves the cached image directly to User B without contacting the origin server.
- This results in faster response times and reduced load on the origin.
Considerations for Using a CDN Effectively
When implementing a CDN, it’s crucial to evaluate these factors to ensure optimal performance and cost-efficiency.
1. Cost Management
- CDNs are provided by third parties and charge for data transfers (in and out).
- Tip: Avoid caching infrequently accessed assets since this can lead to unnecessary expenses without performance gains.
Example: Move rarely accessed assets, like outdated files or archived images, out of the CDN.
2. Cache Expiry Settings
- Setting an appropriate cache expiry time is key, especially for time-sensitive content.
- Challenges:
- If the expiry is too long, users may receive stale content.
- If the expiry is too short, the CDN will frequently reload the content from the origin, increasing costs and load.
Example: Cache static assets (e.g., images) for several days, while more dynamic content (e.g., API responses) might require a shorter cache time.
3. CDN Fallback
- Consider how your application will handle a CDN outage.
- Clients should detect the issue and fall back to requesting resources from the origin server.
Example: Implement fallback logic in your application to check for failed CDN requests and retry with the origin URL.
4. File Invalidation
Sometimes you need to remove or update cached files before their TTL expires.
- Options:
- Invalidate CDN objects using vendor-provided APIs.
- Use object versioning by appending a version parameter to the file URL.
Example: Add a version number to the URL to force a cache refresh:
This is Overview Content delivery network (CDN), We will discuss in detail Content delivery network (CDN) in the next blog.
Message Queue
A message queue is a durable component stored in memory that facilitates asynchronous communication between services. It acts as a buffer to decouple producers and consumers, enabling scalable and reliable applications.
Basic Message Queue Architecture
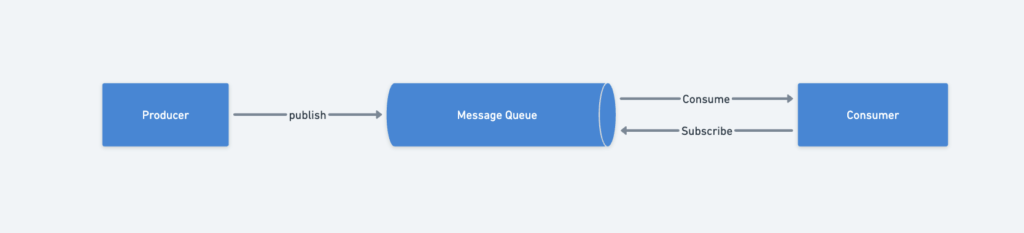
- Producer (Publisher):
Generates and sends messages to the queue. - Message Queue:
Stores messages temporarily until they are processed. - Consumer (Subscriber):
Connects to the queue and performs tasks based on the messages.
Benefits of Message Queues
- Decoupling:
Producers and consumers operate independently.- If the consumer is unavailable, the producer can still post messages.
- If the producer is unavailable, the consumer can still process pending messages from the queue.
- Scalability:
- Producers and consumers can be scaled independently.
- You can add more consumers (workers) when the queue grows.
- If the queue is mostly empty, you can reduce the number of consumers to save resources.
Use Case: Photo Processing Tasks
Consider an application that supports photo customization (e.g., cropping, sharpening, blurring).
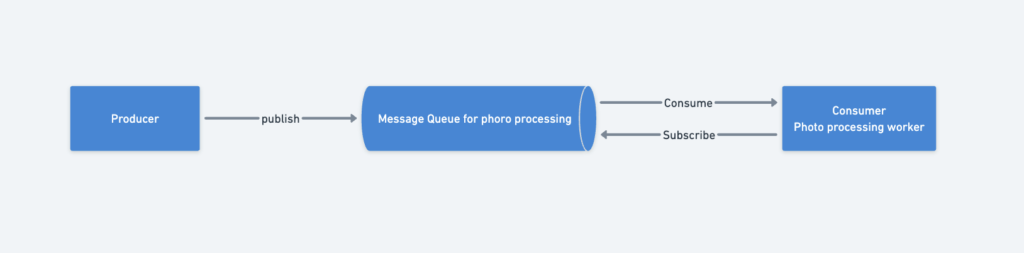
- Web servers act as producers, publishing photo-processing jobs to the message queue.
- Photo processing workers act as consumers, picking up and processing jobs asynchronously.
How Message Queues Improve Efficiency
- Producers don’t have to wait for consumers to finish tasks.
- Consumers can process tasks at their own pace, improving system throughput.
- The system can dynamically scale based on demand.
This is Overview Message Queues, We will discuss in detail Message Queues in the next blog
Logging, Metrics, Automation
As your website grows to serve a large business, investing in logging, metrics, automation, and message queues becomes essential to maintain scalability, reliability, and productivity.
1. Logging
- Why It’s Important:
Logging helps monitor and identify errors or performance issues in the system. - Implementation Options:
- Monitor logs at the server level.
- Use tools to aggregate logs into a centralized service (e.g., ELK Stack, CloudWatch, Splunk) for easy searching and analysis.
Example:
Centralized logging enables your team to quickly search and diagnose issues across multiple servers.
2. Metrics Collection
Collecting metrics helps track system performance and business health. Metrics are categorized into three types:
- Host-Level Metrics:
- CPU usage, memory consumption, disk I/O, etc.
- Useful for identifying resource bottlenecks on individual servers.
- Aggregated Metrics:
- Performance metrics across tiers, such as database and cache performance.
- Helps monitor system-wide performance trends.
- Key Business Metrics:
- Daily active users (DAUs), customer retention, revenue, etc.
- Provides insights into the application’s success and business growth.
Example:
Tracking DAUs and server CPU usage allows you to correlate user activity with server load to make scaling decisions.
3. Automation
- Why It’s Important:
As systems become more complex, automation tools improve productivity and reduce errors. - Continuous Integration (CI):
- Automates code checks and tests for every commit, helping detect issues early.
- Automation in Build/Deploy:
- Automates repetitive tasks like building, testing, and deploying code, which saves time and improves developer productivity.
Example:
Implementing a CI/CD pipeline can reduce deployment time from hours to minutes.
Stateless Web Tier
To scale the web tier horizontally, it’s important to move state (e.g., user session data) out of the web servers. This approach, known as a stateless web tier, allows any server in the cluster to handle incoming requests, making scaling, server management, and failure recovery easier.
Stateful Server
- Remembers client data (state) between requests.
- Requests from the same client must be routed to the same server that holds the client’s session data.
Example:
- User A‘s session data is stored on Server 1, so all their requests must be sent to Server 1.
- Similarly, User B‘s requests must go to Server 2, and User C‘s to Server 3.
- If a request is mistakenly routed to another server (e.g., User A‘s request going to Server 2), the request will fail since Server 2 does not have User A‘s session data.
Challenges:
- Sticky Sessions: Load balancers use sticky sessions to ensure requests are sent to the same server. However, this introduces complexity and overhead.
- Scaling Difficulty: Adding or removing servers requires redistributing session data, making scaling inefficient.
- Failure Handling: If a server fails, all session data on that server is lost.
Stateless Server
- Keeps no state information between requests.
- Session data is stored in persistent storage (e.g., relational databases, and NoSQL stores) that are accessible by all servers.
- Any server can handle requests from any client, enabling easy scaling and failover.
Benefits:
- Improved Scalability: Servers can be added or removed without redistributing session data.
- Simplified Load Balancing: Requests can be routed to any available server without sticky sessions.
- Resilience: Server failures do not affect session data since the data is stored in centralized persistent storage.
Example:
- Store user session data in a Redis cluster or a relational database like PostgreSQL.
- Any server can handle requests from User A, as all servers can access the same session data.
Data Centers
Using multiple data centers improves scalability, availability, and reliability by distributing traffic and services geographically. However, this setup comes with challenges that require careful planning and technical strategies.
Traffic Redirection
- GeoDNS Routing:
Users are routed to the nearest data center based on their location.- Example:
- If a user is in the US-East region, they are routed to the US-East data center.
- Traffic might be split with x% in the US-East and (100 – x)% in the US-West.
- Example:
- Failover Handling:
In the event of a data center outage, all traffic is redirected to a healthy data center.- Example:
- If the US-West goes offline, 100% of traffic is routed to the US-East, ensuring continued availability.
- Example:
Data Synchronization
- Different data centers may have local databases or caches that hold region-specific data.
- During failover, users may be redirected to a data center that does not have up-to-date data.
- Solution: Implement data replication across multiple data centers.
- This can be synchronous (real-time updates) or asynchronous (with slight delays).
- Example: Netflix uses asynchronous multi-data center replication to manage large-scale global services.
Test and Deployment
- Challenge:
Consistent testing and deployment across multiple data centers is crucial to avoid service discrepancies. - Solution:
- Use automated deployment tools to deploy, test, and maintain consistency across all regions.
- Regularly test the application’s performance in different regions to ensure it handles failover and geo-distributed traffic efficiently.
Component Decoupling
- To further scale the system, it’s essential to decouple components so they can scale independently.
- A message queue is commonly used to achieve this decoupling.
- Producers and consumers can communicate asynchronously, allowing components to scale based on demand.
- This design reduces system bottlenecks and improves flexibility.
Security
To secure a large-scale distributed system, it’s essential to apply security measures to each component. Below are some best practices for databases, message queues, caches, etc.
Database
Databases hold critical business and user data, making them a primary target for attackers.
Best Practices:
- Encryption:
- Use encryption at rest to protect stored data.
- Encrypt data in transit with TLS (Transport Layer Security).
- Authentication and Authorization:
- Enforce role-based access control (RBAC) to limit access.
- Use multi-factor authentication (MFA) for administrative access.
- Database Firewall:
- Use database firewalls to block SQL injection and unauthorized access attempts.
- Backup and Replication Security:
- Encrypt backups and replication data.
- Secure backup storage with limited access controls.
Example Tools:
- AWS RDS encryption, PostgreSQL TLS, database firewalls (e.g., AWS WAF).
Message Queue
Message queues often facilitate communication between system components and may carry sensitive data.
Best Practices:
- Encryption:
- Encrypt messages in transit (TLS) and at rest in the message queue.
- Authentication:
- Require strong authentication (e.g., API keys, OAuth) for producers and consumers.
- Access Control:
- Implement fine-grained access control to limit message publishing and reading.
- Auditing and Monitoring:
- Enable logging to track message queue usage and detect suspicious activity.
Example Tools:
- Amazon SQS, RabbitMQ with TLS, Apache Kafka access control.
Cache
Caches, such as Redis or Memcached, improve performance but may also store sensitive data.
Best Practices:
- Encryption:
- Enable TLS for encrypted communication between the application and the cache.
- Encrypt cached data if sensitive information is stored.
- Access Control:
- Restrict access to the cache using firewalls and IP whitelisting.
- Use authentication (e.g., Redis AUTH) to prevent unauthorized access.
- Data Expiry:
- Implement automatic data expiration to minimize the exposure of stale or unused data.
Example Tools:
- Redis encryption and access controls, AWS ElastiCache.
High-Level Design
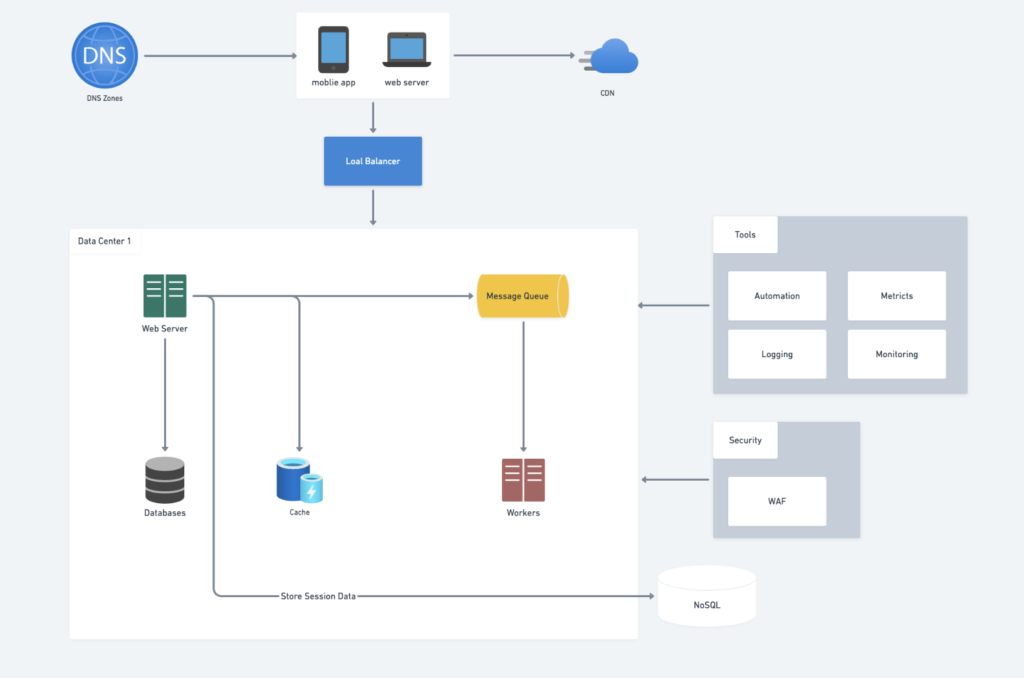
Summary
This is an overview. We will go into detail for each component in the next post.
Scaling a system to support millions of users requires key strategies that enhance performance, reliability, and scalability:
- Stateless Web Tier:
Move session data to persistent storage for easier scaling and failover. - Redundancy:
Implement redundancy across all tiers to prevent single points of failure. - Cache Data:
Use caching (e.g., Redis, Memcached) to reduce database load and improve performance. - Multiple Data Centers:
Use GeoDNS to route users to the nearest data center and replicate data for failover. - CDN for Static Assets:
To reduce server load, cache, and deliver static assets (e.g., images, CSS, and JS) through a CDN. - Database Sharding:
Distribute data across shards to enhance database scalability and performance. - Decouple Services:
Use microservices to allow independent scaling of system components. - Monitoring & Automation:
Collect logs and metrics, and automate CI/CD, testing, and system operations for efficiency.
References
https://www.postgresql.org/docs/17/index.html
https://dev.mysql.com/doc/refman/8.4/en/what-is-mysql.html
RELATED POSTS
View all

